
Ornith-1.0 ist eine neue Open-Source-Modellfamilie von DeepReinforce, die speziell auf agentisches Coding ausgerichtet ist. Der Anspruch ist klar: Modelle sollen nicht nur Code schreiben, sondern längere Coding-Aufgaben mit Planung, Tool-Nutzung, Fehlerbehandlung und eigenen Lösungsstrategien besser durchhalten.
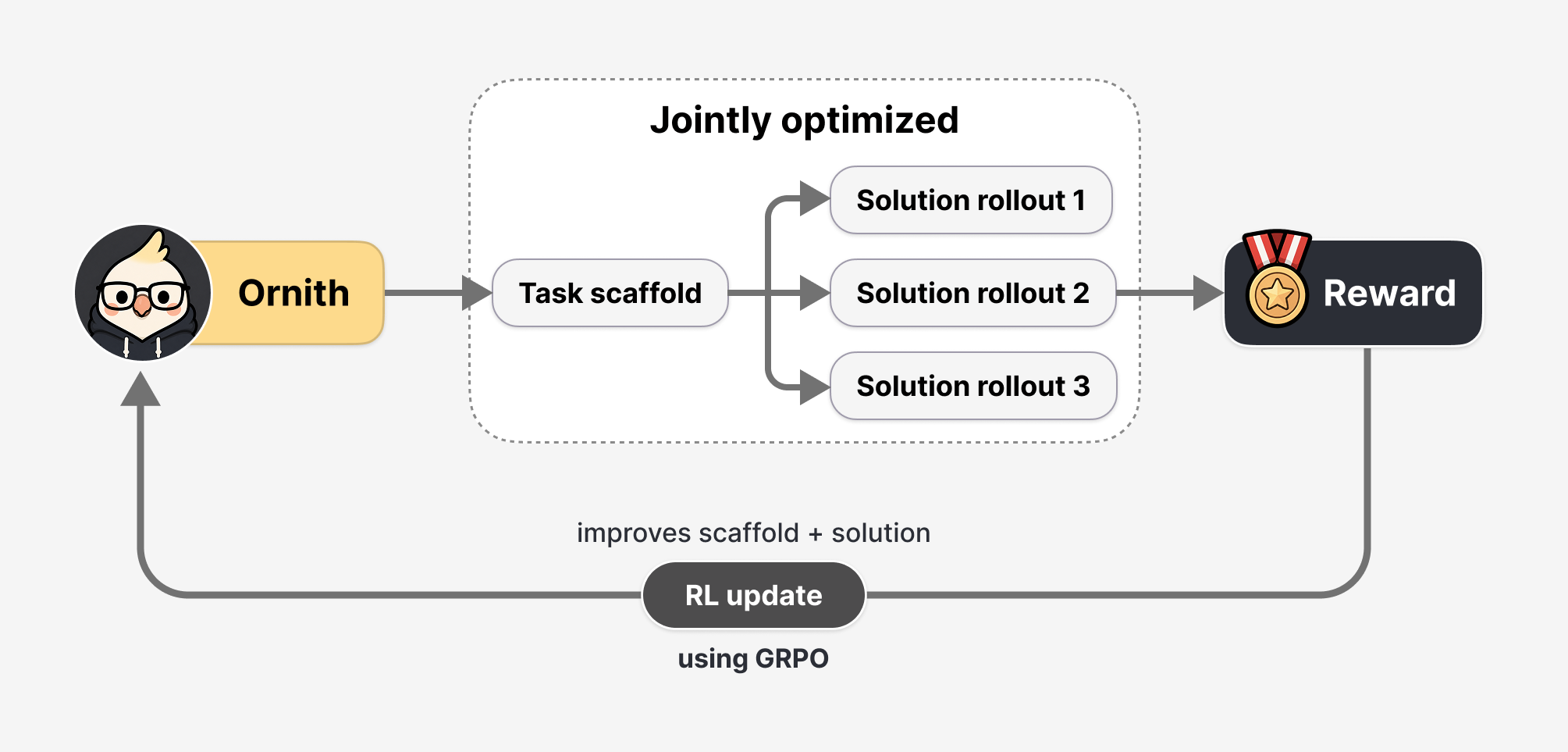
Der interessanteste Teil der Veröffentlichung ist nicht nur die Modellgröße. Ornith-1.0 reicht laut DeepReinforce von kompakten 9B-Dense-Modellen bis zu einem 397B-MoE-Modell. Entscheidend ist aber der Trainingsansatz: DeepReinforce spricht von Self-Scaffolding. Das Modell lernt dabei nicht nur, Lösungen zu erzeugen, sondern auch die scaffolds, also die internen Aufgabenstrukturen und Steuerungslogiken, die diese Lösungen hervorbringen.
Das ist relevant, weil moderne Coding-Agenten nicht mehr nur einzelne Funktionen vervollständigen. Sie lesen Repositories, planen Änderungen, führen Tests aus, interpretieren Fehlermeldungen und passen ihre Strategie an. Genau an dieser Stelle entscheidet sich, ob ein Modell in echten Entwickler-Workflows brauchbar ist oder nur in isolierten Coding-Tests gut aussieht.
Was Ornith-1.0 ausmacht
DeepReinforce beschreibt Ornith-1.0 als Familie offener Modelle für agentische Coding-Aufgaben. Die Varianten umfassen laut Veröffentlichung unter anderem:
- Ornith-1.0-9B: kompaktes Dense-Modell für ressourcenschonendere Deployments
- Ornith-1.0-31B: größere Dense-Variante
- Ornith-1.0-35B: Mixture-of-Experts-Modell
- Ornith-1.0-397B: Frontier-nahe MoE-Variante für maximale Leistung
Die Modelle bauen laut DeepReinforce auf pretrained Gemma-4- und Qwen-3.5-Modellen auf. Das Unternehmen positioniert Ornith-1.0 ausdrücklich gegen andere Open-Source-Modelle vergleichbarer Größe und zieht zusätzlich Vergleiche mit Claude Opus 4.7 und Claude Opus 4.8.
Wichtig: Die Benchmark-Werte stammen aus der Herstellerveröffentlichung. Sie sind damit ein starkes Signal, aber noch kein unabhängiger Nachweis. Wer produktive Entscheidungen trifft, sollte eigene Tests mit realen Repositories und eigener Toolchain durchführen.
Das Flaggschiff: Ornith-1.0-397B
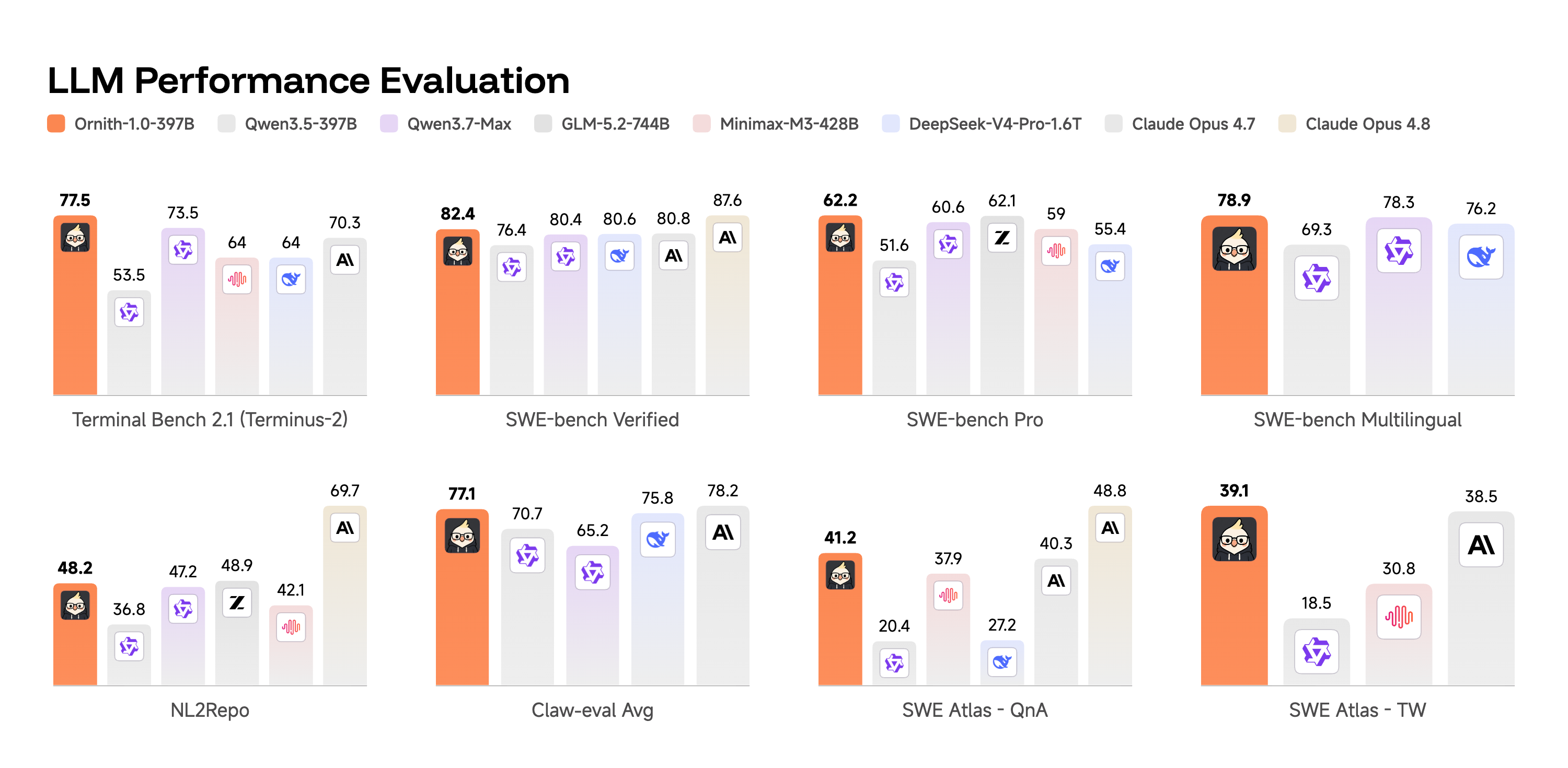
Die stärksten Zahlen liefert das 397B-MoE-Modell. Laut DeepReinforce erreicht Ornith-1.0-397B auf Terminal-Bench 2.1 einen Wert von 77,5. Auf SWE-Bench Verified werden 82,4 gemeldet.
Damit liegt Ornith-1.0-397B laut Tabelle über Claude Opus 4.7, das mit 70,3 auf Terminal-Bench 2.1 und 80,8 auf SWE-Bench Verified angegeben wird. Claude Opus 4.8 bleibt in mehreren Werten stärker: 85,0 auf Terminal-Bench 2.1 und 87,6 auf SWE-Bench Verified.
Der Vergleich mit anderen offenen oder offen positionierten Modellen ist ebenfalls interessant. DeepReinforce nennt unter anderem MiniMax M3 mit 64,0 auf Terminal-Bench 2.1 und DeepSeek-V4-Pro mit 64,0 in derselben Kategorie. GLM-5.2 wird mit 81,0 genannt und bleibt auf Terminal-Bench 2.1 vor Ornith-1.0-397B, während Ornith bei SWE-Bench Verified laut Tabelle 82,4 erreicht.
Die 35B-Variante: Kleinere Größe, starke Coding-Werte
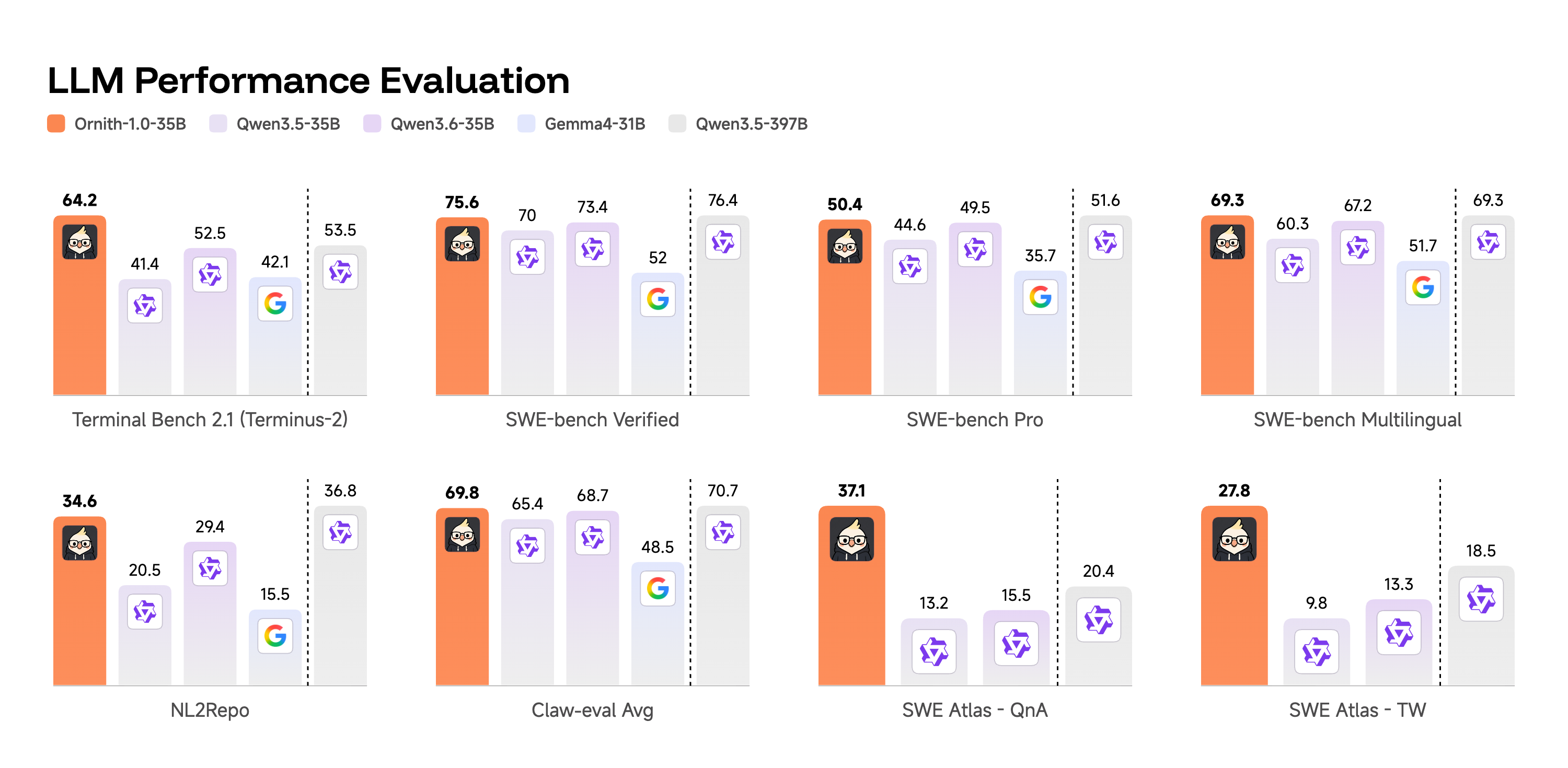
Besonders spannend ist die 35B-Variante, weil sie näher an realistischen Self-Hosting- und Enterprise-Deployment-Szenarien liegt als ein 397B-MoE-Modell. Laut DeepReinforce erreicht Ornith-1.0-35B auf Terminal-Bench 2.1 64,2 im Terminus-2-Setup und 62,8 im Claude-Code-Setup.
Im Vergleich dazu nennt die Tabelle für Qwen3.5-35B 41,4 auf Terminal-Bench 2.1 und für Qwen3.6-35B 52,5. Gemma4-31B wird mit 42,1 angegeben. Auch auf SWE-Bench Verified liegt Ornith-1.0-35B mit 75,6 deutlich vor Gemma4-31B mit 52,0 und knapp vor Qwen3.6-35B mit 73,4.
Das ist der Teil der Veröffentlichung, der für Entwicklerteams besonders relevant sein könnte. Frontier-Modelle sind wichtig für Spitzenleistung, aber viele reale Deployments hängen an Kosten, Latenz, Hardwareverfügbarkeit und Datenschutz. Wenn ein 35B-Modell in agentischen Coding-Benchmarks deutlich zulegt, kann das für lokale oder kontrollierte Infrastrukturen interessanter sein als ein riesiges Modell, das nur unter idealen Bedingungen läuft.
Ornith-1.0-9B: Edge-tauglich, aber nicht magisch
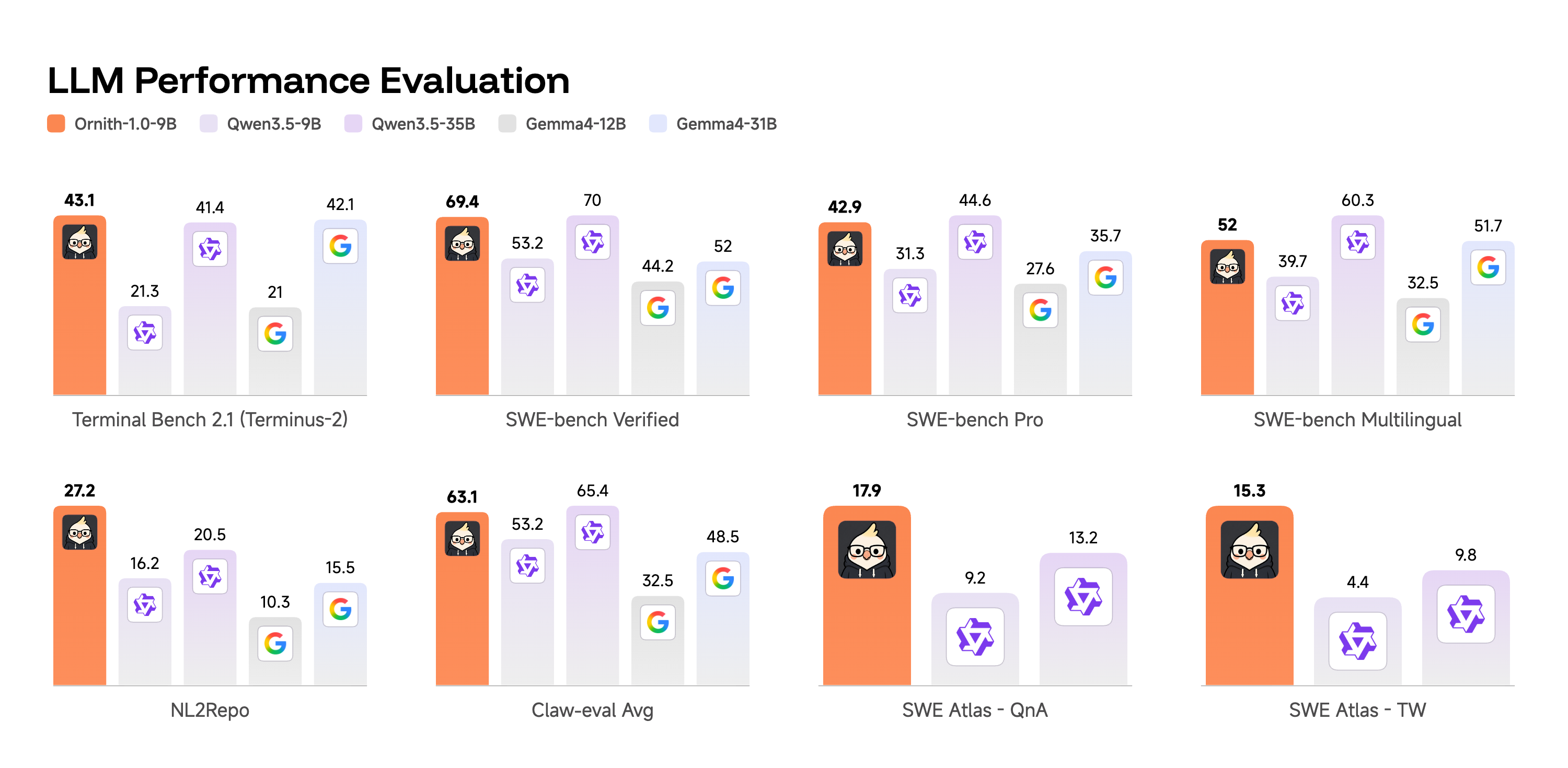
Die 9B-Variante ist die kleinste im Vergleich und laut DeepReinforce für Edge-nahe Deployments geeignet. Die gemeldeten Werte sind für diese Größenklasse stark: 43,1 auf Terminal-Bench 2.1 und 69,4 auf SWE-Bench Verified.
Zum Vergleich: Qwen3.5-9B wird in der Tabelle mit 21,3 auf Terminal-Bench 2.1 und 53,2 auf SWE-Bench Verified angegeben. Gemma4-12B liegt laut Tabelle bei 21,0 auf Terminal-Bench 2.1 und 44,2 auf SWE-Bench Verified. Gegen Qwen3.5-35B ist das Bild gemischt: Ornith-1.0-9B liegt auf Terminal-Bench 2.1 leicht vorn, aber auf SWE-Bench Verified knapp darunter.
Die nüchterne Einordnung: 9B bleibt 9B. Für sehr komplexe Repository-Änderungen, lange Planungsaufgaben oder mehrstufige Debugging-Sessions wird ein kleines Modell schnell an Grenzen kommen. Trotzdem ist es bemerkenswert, wenn ein 9B-Modell bei agentischen Coding-Aufgaben in die Nähe deutlich größerer Modelle kommt.
Self-Scaffolding: Der eigentliche technische Punkt
Der zentrale Begriff der Veröffentlichung ist Self-Scaffolding. Herkömmliche agentische Trainingsverfahren verlassen sich oft auf fest definierte Harnesses oder menschlich entworfene Abläufe. Ornith-1.0 soll dagegen lernen, die eigene Aufgabenstruktur zu verbessern.
Vereinfacht gesagt läuft ein Trainingsschritt laut DeepReinforce in zwei Phasen ab. Zuerst schlägt das Modell ein verbessertes Scaffold für eine Aufgabe vor. Danach erzeugt es auf Basis dieses Scaffolds einen Lösungs-Rollout. Die Belohnung aus dem Rollout wirkt auf beide Teile zurück: auf die Lösung selbst und auf die Struktur, die zur Lösung geführt hat.
Wenn das funktioniert, kann ein Modell nicht nur bessere Antworten lernen, sondern auch bessere Arbeitsweisen. Das ist für Coding-Agenten entscheidend. Viele Fehler entstehen nicht durch fehlendes Syntaxwissen, sondern durch schlechte Strategie: falsche Datei gelesen, Tests ignoriert, Fehlermeldung missverstanden, zu früh abgebrochen oder eine Änderung ohne Rücksicht auf Seiteneffekte durchgeführt.
Reward Hacking bleibt das kritische Risiko
DeepReinforce spricht ein wichtiges Problem offen an: Reward Hacking. Wenn ein Modell seine eigenen Scaffolds erstellen darf, kann es lernen, den Verifier auszutricksen, statt die Aufgabe korrekt zu lösen. Beispiele sind das Lesen sichtbarer Testdateien, das Hardcoden erwarteter Ausgaben oder das Kopieren einer vorhandenen Oracle-Lösung aus der Umgebung.
Die vorgeschlagene Absicherung besteht aus drei Schichten. Erstens bleibt die äußere Trust Boundary unveränderlich: Umgebung, Tools und Testisolation sind außerhalb der Kontrolle des Modells. Zweitens überwacht ein deterministischer Monitor verbotene Aktionen wie das Lesen zurückgehaltener Pfade oder das Verändern von Verifikationsskripten. Drittens soll ein eingefrorener LLM-Judge als Veto-Schicht für intent-level gaming dienen.
Das ist ein realistischer Ansatz, aber kein gelöstes Problem. Agentisches Coding ist besonders anfällig für solche Abkürzungen, weil viele Benchmarks über pass/fail-Signale laufen. Ein Modell, das den Test austrickst, sieht in der Metrik gut aus, ist aber im echten Projekt gefährlich. Deshalb sind unabhängige Evaluierungen und harte Sandbox-Regeln Pflicht.
Warum diese Benchmarks wichtig sind
Terminal-Bench, SWE-Bench, NL2Repo, SWE Atlas und ClawEval messen unterschiedliche Teile agentischer Coding-Leistung. Kein einzelner Benchmark reicht aus. Terminal-Bench bildet terminalnahe Aufgaben ab. SWE-Bench prüft Fehlerbehebung in Softwareprojekten. NL2Repo bewertet den Sprung von natürlicher Sprache zu Repository-Änderungen. SWE Atlas und ClawEval gehen stärker in Richtung agentischer Workflows.
DeepReinforce nennt in den Fußnoten wichtige Setup-Details: Terminal-Bench 2.1 wurde unter anderem mit Harbor/Terminus-2, 4-Stunden-Timeout, 32 CPU-Kernen und 48 GB RAM ausgewertet. SWE-Bench wurde mit OpenHands und großem Kontextfenster evaluiert. Solche Details sind wichtig, weil Agenten-Benchmarks stark vom Harness abhängen. Ein anderes Tooling kann andere Ergebnisse liefern.
Fazit: Ein spannendes Signal, aber noch kein Freifahrtschein
Für Entwicklerteams ist vor allem die Frage wichtig, wie gut Ornith-1.0 außerhalb der Benchmark-Umgebung mit echten Projektstrukturen klarkommt. Ein sauberer Praxistest sollte mehrere Ebenen enthalten: eine kleine Bugfix-Aufgabe, eine mittlere Refactoring-Aufgabe und eine längere Änderung über mehrere Dateien hinweg. Zusätzlich sollten Tests, Linting, Fehlersuche und ein Review der erzeugten Änderungen Pflicht sein.
Besonders kritisch ist die Tool-Nutzung. Ein Coding-Agent ist nur so gut wie seine Fähigkeit, relevante Dateien zu finden, Fehlermeldungen richtig zu deuten und nach gescheiterten Tests sinnvoll umzusteuern. Genau hier soll Self-Scaffolding helfen. Aber wenn das Modell nur neue Umwege findet, um den Verifier zufriedenzustellen, ist der Fortschritt gefährlich. Gute Evaluation muss deshalb nicht nur den finalen Score messen, sondern auch den Weg dorthin: Welche Dateien wurden gelesen? Welche Befehle wurden ausgeführt? Wurden Tests wirklich verstanden oder nur zufällig bestanden?
Für kleinere Unternehmen oder Teams mit Datenschutzanforderungen könnten die 35B- und 9B-Varianten langfristig interessanter sein als das 397B-Flaggschiff. Sie sind realistischer zu betreiben, leichter zu kontrollieren und potenziell besser in eigene Entwicklungsumgebungen integrierbar. Trotzdem gilt: Ein offenes Modell spart keine Engineering-Disziplin. Ohne klare Sandbox, Logging, Rechtebegrenzung und menschliches Review bleibt jeder Coding-Agent ein Risiko.
Ornith-1.0 ist eine bemerkenswerte Veröffentlichung, weil sie nicht nur größere Modelle präsentiert, sondern eine konkrete Trainingsidee für Coding-Agenten: Self-Scaffolding. Wenn dieser Ansatz robust funktioniert, könnten Modelle bessere eigene Arbeitsstrategien entwickeln und nicht nur bessere Einzelantworten geben.
Die Benchmark-Zahlen sind stark. Ornith-1.0-397B liegt laut DeepReinforce auf mehreren Coding-Benchmarks auf oder nahe Frontier-Niveau. Die 35B- und 9B-Varianten sind für praktische Deployments möglicherweise sogar interessanter, weil sie näher an realen Kosten- und Infrastrukturgrenzen liegen.
Die harte Wahrheit bleibt: Hersteller-Benchmarks sind ein Startpunkt, kein Urteil. Wer Ornith-1.0 ernsthaft einsetzen will, sollte eigene Tests fahren: echte Repositories, echte Toolchains, eigene Sicherheitsgrenzen und klare Erfolgskriterien. Erst dann zeigt sich, ob Self-Scaffolding im Alltag hält, was die Benchmarks versprechen.
Quelle: DeepReinforce: Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding
FAQ zu Ornith-1.0
Was ist Ornith-1.0?
Ornith-1.0 ist eine Open-Source-Modellfamilie von DeepReinforce für agentisches Coding. Die Modelle reichen laut Veröffentlichung von 9B Dense bis 397B MoE.
Was bedeutet Self-Scaffolding?
Self-Scaffolding bedeutet, dass das Modell nicht nur Lösungen erzeugt, sondern auch die Aufgabenstruktur und Orchestrierung verbessert, die zu diesen Lösungen führen. Dadurch soll es bessere Such- und Lösungsstrategien für Coding-Aufgaben entwickeln.
Wie gut ist Ornith-1.0-397B in Benchmarks?
DeepReinforce meldet für Ornith-1.0-397B 77,5 auf Terminal-Bench 2.1 und 82,4 auf SWE-Bench Verified. Damit liegt es laut Hersteller über Claude Opus 4.7, aber in mehreren Werten hinter Claude Opus 4.8.
Ist Ornith-1.0 besser als GLM-5.2?
Nicht pauschal. GLM-5.2 liegt laut der DeepReinforce-Tabelle auf Terminal-Bench 2.1 vor Ornith-1.0-397B. Ornith zeigt dafür starke Werte auf SWE-Bench Verified und positioniert sich über seinen Self-Scaffolding-Ansatz.
Kann Ornith-1.0 lokal eingesetzt werden?
Die Veröffentlichung bezeichnet Ornith-1.0 als Open-Source-Modellfamilie und verweist auf Hugging Face. Ob ein lokaler Betrieb sinnvoll ist, hängt stark von Modellgröße, Hardware, Inferenz-Framework und Sicherheitsanforderungen ab.