
OpenAI stellt neue Audio-Modelle vor
OpenAI hat kürzlich eine neue Generation von Audio-Modellen vorgestellt, die in ihrer API zugänglich sind und Entwicklern helfen sollen, leistungsstarke Sprachanwendungen zu erstellen. Diese Modelle verbessern die Genauigkeit und Individualisierbarkeit von Sprach-zu-Text- und Text-zu-Sprach-Funktionen erheblich.
Neue Sprach-zu-Text-Modelle
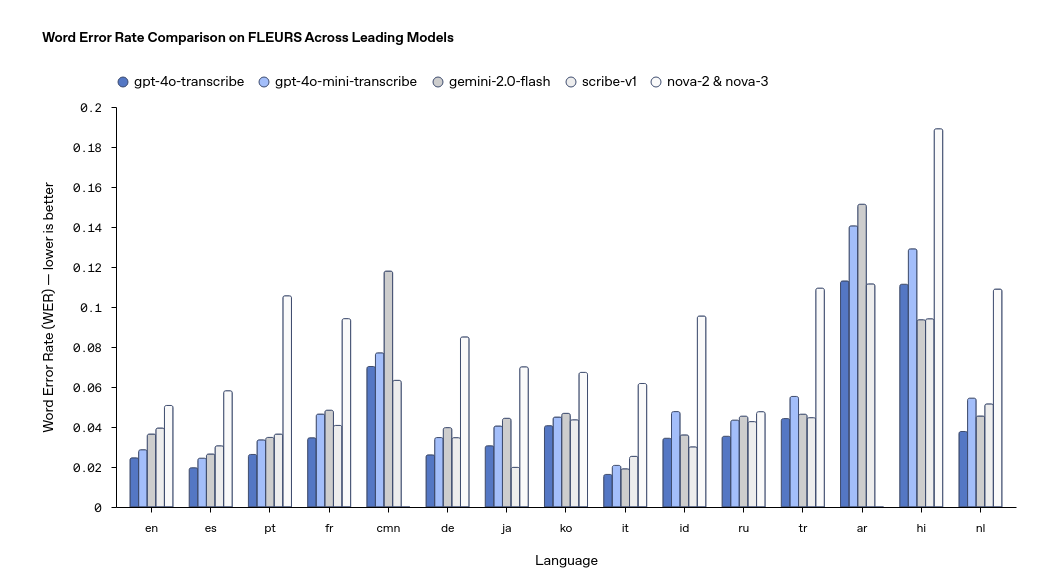
Mit den Modellen GPT-4o-transcribe und GPT-4o-mini-transcribe bietet OpenAI nun Lösungen, die eine wesentlich höhere Genauigkeit als ältere, wie das Whisper-Modell von 2022, erreichen. Diese Modelle zeigen eine niedrigere Fehlerrate (Word Error Rate, WER) und sind speziell für den Einsatz in anspruchsvollen Szenarien wie lauter Umgebung, Akzenten oder variierenden Sprachgeschwindigkeiten optimiert.
- GPT-4o-transcribe: Das präzisere der beiden Modelle, ideal für Anwendungen wie Echtzeit-Transkriptionen in Kundenservices oder das Erstellen von Meetingnotizen.
- GPT-4o-mini-transcribe: Effizienter und ressourcenschonender, was es ideal für weniger aufwändige Szenarien macht.
Technische Fortschritte wie die Verwendung von hochwertigen Audio-Datensätzen, distilliertes Lernen zur Optimierung von größeren auf kleinere Modelle und der Einsatz von verstärkendem Lernen haben zu diesen Verbesserungen beigetragen.
Text-zu-Sprach-Modell: GPT-4o-mini-tts
Das Text-zu-Sprach-Modell GPT-4o-mini-tts bietet neuartige „Steuerbarkeit“. Entwickler können definieren, wie ein Text gesprochen werden soll, z. B. im Tonfall eines motivierten Kundendienstmitarbeiters oder als chaotischer Wissenschaftler mit hoher Energie. Diese Anpassungsfähigkeit erlaubt vielseitige Anwendungen wie personalisierte Stimmeinstellungen für Kundenservice-Bots, Hörbucherzählungen oder kreative Erzählstile.
Kostenstruktur
Die Preisgestaltung macht diese Modelle relativ zugänglich:
- GPT-4o-transcribe: ~$0,006 pro Minute
- GPT-4o-mini-transcribe: ~$0,003 pro Minute
- GPT-4o-mini-tts: ~$0,015 pro Minute
Integration und Einsatz
Durch eine aktualisierte Agents SDK können Entwickler bestehende textbasierte Agenten mit minimalem Codeaufwand in Sprachagenten verwandeln. Beispielsweise sind lediglich neun zusätzliche Codezeilen notwendig, um einen textbasierenden Kundensupport-Agenten für Sprachanfragen zu adaptieren. Der Prozess umfasst die Umwandlung von Sprache in Text, die Verarbeitung durch das Sprachmodell und die anschließende Erzeugung einer gesprochener Antwort.
Einsatzmöglichkeiten und Vorteile
Diese Modelle sind für ein breites Spektrum von Anwendungen ausgelegt, darunter:
- Kundendienstsysteme
- Sprachlernplattformen
- Automatische Protokollierung von Meetings
- Kreative Anwendungen wie Hörbücher oder Storytelling
Die neuen Modelle heben sich durch Verbesserungen in der Transkriptionsgenauigkeit und Individualisierbarkeit hervor. Herausforderungen bestehen weiterhin in der Bearbeitung mehrsprachiger Inhalte, insbesondere bei Sprachen mit komplexen Phonemen und geringerem historischem Trainingsumfang.
Technologische Grundlage
Die Modelle basieren auf den Architekturen GPT-4o und GPT-4o-mini und nutzen ein multimodales Design, das sie befähigt, sowohl Audio als auch Text zu verarbeiten. Kerntechnologien umfassen:
- Nutzung spezialisierter Audio-Datensätze zur Vorab-Trainierung.
- Distillationstechniken für effektivere Berechnungen in komprimierten Modellen.
- Ein Paradigma des verstärkten Lernens, das die Präzision bei Transkriptionen in anspruchsvollen Umgebungen erhöht.
OpenAI plant, diese Technologien weiter auszubauen und neue Funktionalitäten zu implementieren. Ziel ist die vermehrte Integration von tiefgreifenden Audio-Interaktionen in KI-Systeme, um menschlichere und effektivere Sprachlösungen zu ermöglichen. Die neuen Modelle stehen ab sofort über die OpenAI API zur Verfügung.
Quelle:
https://openai.com/index/introducing-our-next-generation-audio-models/