
Gemini 2.5 Flash ist das neueste KI-Modell von Google und setzt einen neuen Standard in puncto Kosteneffizienz, Geschwindigkeit und anpassbarer Denkfähigkeit für Entwickler. Als erstes vollständig hybrides Reasoning-Modell ermöglicht Gemini 2.5 Flash die gezielte Steuerung des „Denkens“. Dies erlaubt es, die Balance zwischen Ausführungsqualität, Kosten und Latenz individuell je nach Anwendungsfall zu optimieren.
Technische Merkmale und Funktionen
- Hybrides Reasoning: Entwickler können das „Denken“ (Reasoning) des Modells gezielt aktivieren oder deaktivieren. Dadurch kann auf situationsbezogene Anforderungen von Geschwindigkeit oder Ausführungsqualität flexibel reagiert werden. Das Modell lässt sich passend zum jeweiligen Workload konfigurieren.
- Thinking Budget: Über das sogenannte „Thinking Budget“ kann exakt vorgegeben werden, wie viele Token für die Denkphase maximal genutzt werden dürfen. Möglich sind Werte zwischen 0 (Thinking aus) und 24.576 Token. Das Budget wird über einen API-Parameter oder einen Schieberegler in Google AI Studio und Vertex AI eingestellt. Je höher das Budget, desto intensiver kann das Modell nachdenken und desto höher ist potenziell die Antwortqualität. Das Modell entscheidet automatisch, wie viel Denkzeit für eine Aufgabe sinnhaft ist und nutzt das volle Limit nur bei Bedarf.
- Multimodalität: Gemini 2.5 Flash akzeptiert Text-, Bild-, Audio- und Videoinhalte im Prompt. Damit sind vielseitige Anwendungsfälle von der reinen Textanalyse bis zur multimodalen Datenverarbeitung möglich.
- Kontextfenster: Das Modell unterstützt ein Kontextfenster von 1 Million Tokens für den Input und 65.000 Tokens für den Output. Damit lassen sich auch extrem umfangreiche Datensätze und Dokumente bearbeiten, etwa für Analysen, Unterstützung bei Forschung oder große Chat-Anwendungen.
- Knowledge Cutoff: Der Wissensstand des Modells reicht bis Januar 2025 und umfasst somit aktuelles Weltwissen und moderne Benchmarks.
- Kompatible Plattformen: Gemini 2.5 Flash ist in der Vorschauversion verfügbar über die Gemini API, Google AI Studio, Vertex AI und die Gemini App.
Preisstruktur
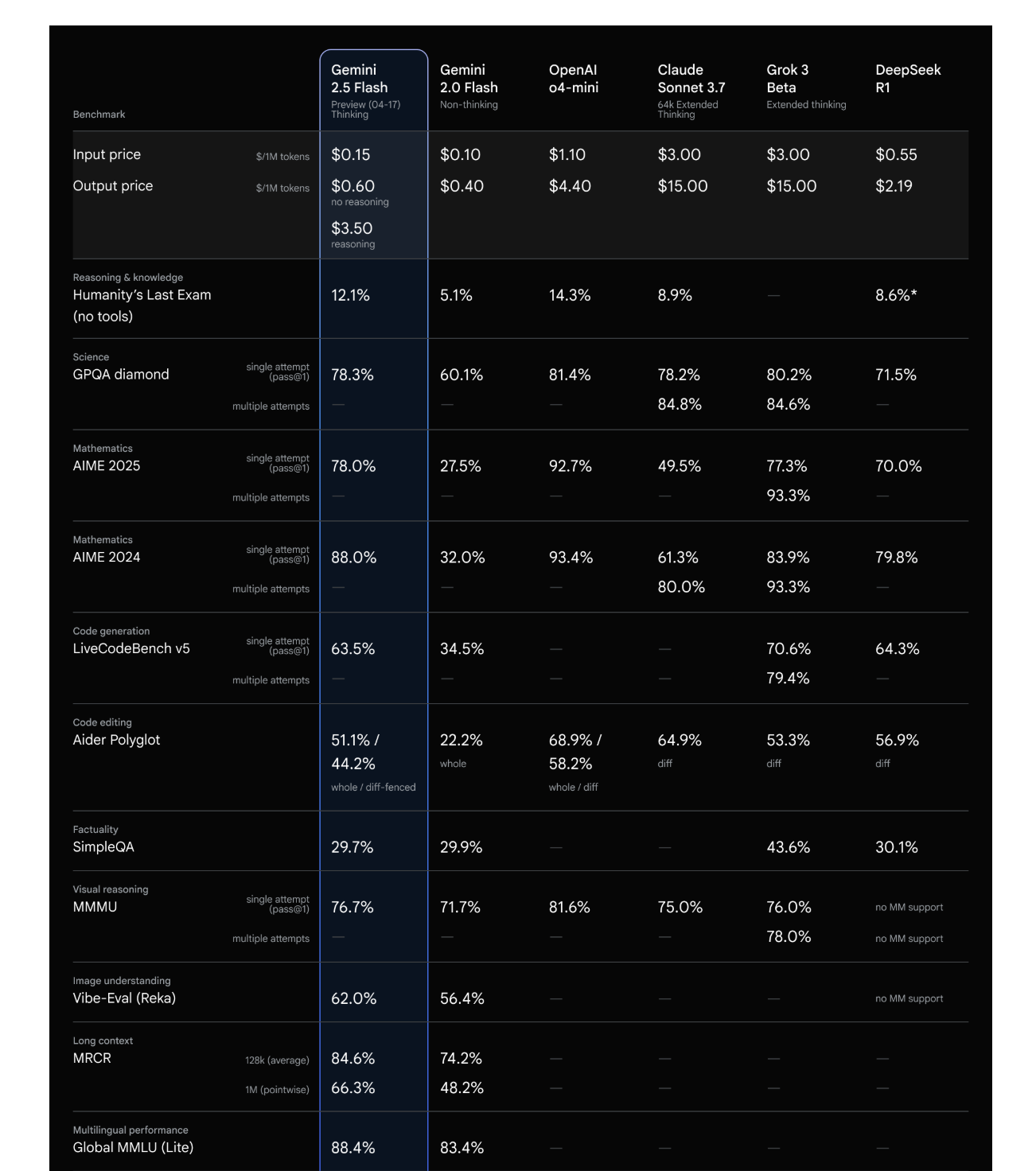
- Inputpreise: 0,15 USD pro 1 Million Tokens
- Outputpreise: 0,60 USD pro 1 Million Tokens ohne Reasoning, 3,50 USD pro 1 Million Tokens mit aktiviertem Reasoning
Gemini 2.5 Flash ist damit im Preis-Leistungs-Verhältnis deutlich günstiger als mehrere Konkurrenzprodukte.
Anwendungsgebiete
- Komplexe und mehrstufige Aufgaben wie mathematische Berechnungen, Recherche-Auswertungen oder intelligente Assistenten profitieren von der Reasoning-Funktion.
- Für simple Aufgaben kann das Thinking-Budget auf 0 gesetzt werden, wodurch eine Verarbeitung mit maximaler Geschwindigkeit und minimalen Kosten erfolgen kann.
- Besonders geeignet für Applikationen mit hohem Durchsatzbedarf wie Chatbots im Kundenservice, automatisierte Datenextraktion und umfassende Zusammenfassungen großer Dateien oder Medieninhalte.
Leistung und Benchmarks
- Gemini 2.5 Flash zeigte starke Ergebnisse bei anspruchsvollen Reasoning-Benchmarks wie „Humanity’s Last Exam (HLE)“ mit 12,1 Prozent und liegt damit vor Modellen wie Claude 3.7 Sonnet und DeepSeek R1. Lediglich das aktuelle OpenAI o4-mini konnte mit 14,3 Prozent bessere Werte erzielen.
- Für wissenschaftliche Aufgaben und Multimodalität liefert Gemini 2.5 Flash ebenfalls wettbewerbsfähige Resultate.
Integration und Beispielcode
Das Modell kann per API angesprochen werden. Beispiel für eine Integration:
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)
Zusammenfassung
Gemini 2.5 Flash bietet ein einzigartiges Gleichgewicht aus Leistung, Flexibilität und Kostenkontrolle. Die Möglichkeit, Reasoning gezielt zu aktivieren oder zu begrenzen, schafft neue Freiheiten für Entwickler und Unternehmen, um passgenaue KI-Lösungen für unterschiedlichste Anforderungen mit effizienter Ressourcensteuerung zu entwickeln.
Quelle:
https://developers.googleblog.com/en/start-building-with-gemini-25-flash/
One Reply to “Gemini 2.5 Flash: Das hybride KI-Modell von Google für kosteneffizientes und flexibles Reasoning”