
Neue API-Modelle mit Quantensprüngen bei Coding, Instruktionen und LangkontextOpenAI stellt GPT-4.1 vor
Die Highlights der GPT-4.1 Familie:
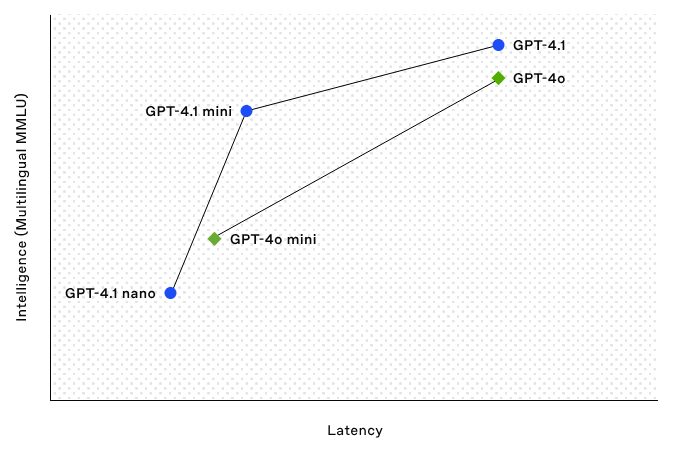
- Verbesserte Leistung: Übertrifft GPT-4o und GPT-4o mini in vielen Benchmarks.
- Fokus auf Kernkompetenzen: Deutliche Fortschritte bei Coding und Instruktionsbefolgung.
- Massiver Kontext: Unterstützung für bis zu 1 Million Tokens Kontextfenster.
- Besseres Kontextverständnis: Verbesserte Fähigkeit, Informationen aus langen Kontexten zu nutzen.
- Aktuelles Wissen: Wissensstand bis Juni 2024.
- API-Exklusivität: Zunächst nur über die API verfügbar.
1. Coding-Fähigkeiten auf neuem Niveau
- SWE-bench Verified: 54,6 %, über 21,4 %abs besser als GPT-4o.
- Code Diffs: Zuverlässiger bei Code-Änderungen, über doppelt so gut wie GPT-4o im Aider-Benchmark.
- Frontend-Entwicklung: 80 % menschliche Präferenz gegenüber GPT-4o.
- Weniger Fehler: Reduktion unnötiger Änderungen von 9 % auf 2 %.
Real-World Beispiele:
- Windsurf: 60 % höhere Punktzahl, 30 % effizienter bei Tool-Aufrufen.
- Qodo: 55 % bessere GitHub-Code-Reviews.
2. Präzisere Befolgung von Anweisungen
- MultiChallenge Benchmark: 38,3 % (10,5 %abs besser als GPT-4o).
- IFEval: 87,4 % bei überprüfbaren Anweisungen.
Real-World Beispiele:
- Blue J: 53 % genauer bei komplexen Steuerszenarien.
- Hex: Fast doppelt so gut bei anspruchsvollen SQL-Evaluierungen.
Hinweis: GPT-4.1 nimmt Anweisungen wörtlicher – genaue Prompts empfohlen.
3. Revolutionärer Langkontext: Bis zu 1 Million Tokens
- Needle-in-a-Haystack: Zuverlässiges Abrufen über volle Kontextlänge.
- OpenAI-MRCR und Graphwalks: Deutlich bessere Fähigkeiten bei Multi-Hop-Reasoning.
Real-World Beispiele:
- Thomson Reuters: 17 % bessere Genauigkeit bei langen juristischen Dokumenten.
- Carlyle: 50 % bessere Extraktion granularer Finanzdaten.
Latenz: Unter 5 Sekunden „Time to first token“ bei GPT-4.1 nano (128k Tokens).
4. Starke Vision-Fähigkeiten
- MMMU, MathVista, CharXiv: Deutliche Verbesserungen im visuellen Verständnis.
- Video-MME Benchmark: 72,0 %, +6,7 % über GPT-4o.
5. Preisgestaltung und Verfügbarkeit
| Modell | Input | Cached Input | Output | Blended Pricing* |
|---|---|---|---|---|
| gpt-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 | $0.42 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 | $0.12 |
*Basierend auf typischen Input/Output- und Cache-Verhältnissen.
Zusätzliche Preisvorteile:
- Prompt Caching: 75 % Rabatt.
- Batch API: 50 % Preisnachlass.
- Langkontext: Keine Zusatzkosten.
Fazit
Die Einführung der GPT-4.1-Modellfamilie ist ein bedeutender Fortschritt. Die Kombination aus massiver Kontextverarbeitung, stärkerem Instruction Following und Coding-Kompetenz eröffnet neue Möglichkeiten für Entwickler. GPT-4.1 mini bietet ein starkes Preis-Leistungs-Verhältnis, GPT-4.1 nano glänzt bei Geschwindigkeit und Effizienz.
Quelle:
https://openai.com/index/gpt-4-1/