
DeepCoder-14B-Preview ist ein fortschrittliches, offenes Sprachmodell für Programmieraufgaben, das von Together AI in Zusammenarbeit mit Agentica entwickelt wurde. Es wurde aus dem Modell DeepSeek-R1-Distilled-Qwen-14B durch verteiltes Reinforcement Learning (RL) weitertrainiert. Dieses Modell erzielt beeindruckende Ergebnisse insbesondere bei Codierungsaufgaben und konkurriert mit leistungsstarken Modellen wie OpenAI’s o3-mini-2025.
Leistungsdaten und Benchmark-Ergebnisse
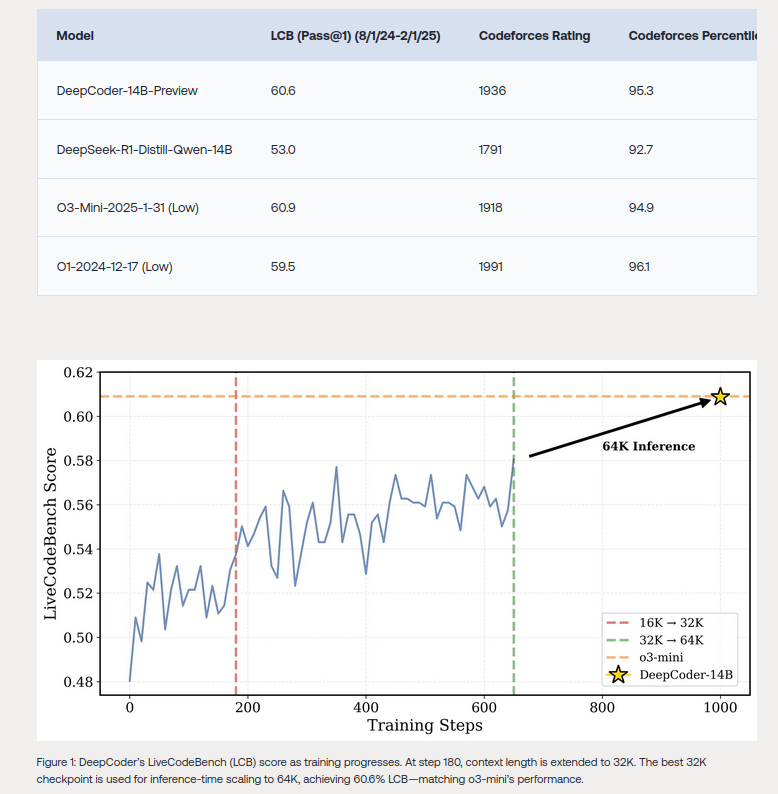
- Genauigkeit: Das Modell erreicht eine Pass@1-Genauigkeit von 60,6 % auf dem LiveCodeBench v5 (08/2024 – 02/2025), was einer Verbesserung von 8 % gegenüber der Baseline entspricht.
- Codeforces-Rating: 1936 Punkte, was im 95,3. Perzentil liegt.
- HumanEval+ Score: 92,6 %, gleichauf mit führenden Konkurrenten.
Das Modell wurde auf einer Vielzahl von Benchmarks wie LiveCodeBench, Codeforces und HumanEval+ getestet, mit konstanten, wettbewerbsfähigen Ergebnissen.
Trainingsdaten und Funktionsweise
Das Training basierte auf einer Sammlung von 24.000 überprüfbaren Problem-Test-Paaren, welche von Quellen wie Taco-Verified, PrimeIntellect SYNTHETIC-1 und LiveCodeBench generiert wurden.
Die Leistungssteigerung des Modells ist dem Einsatz einer optimierten GRPO+-Strategie zu verdanken. Diese umfasst:
- Offline-Difficulty-Filtering: Einen optimierten Schwierigkeitsfilter, um das Trainingsmaterial auf die richtige Komplexität zu beschränken.
- Iterative Kontextverlängerung: Fortschrittliches Training mit kontextuellen Längen von bis zu 64.000 Tokens.
- Keine Verwendung von Entropy Loss und KL Loss, um die Stabilität bei der Modelloptimierung zu gewährleisten.
Diese Methoden ermöglichen es DeepCoder-14B-Preview, besser mit langen Kontexteingaben umzugehen und komplexe Codierungsprobleme effizient zu lösen.
Technologische Rahmenbedingungen
DeepCoder-14B-Preview wurde in zwei Wochen auf einer Rechnerinfrastruktur mit 32 NVIDIA H100 GPUs trainiert. Während der Entwicklungsphase wurden Optimierungen wie „One-Off Pipelining“ eingesetzt, die die Berechnungszeit für RL-Iteration bei Codierungsaufgaben um das Doppelte reduzierten.
Das Modell wurde zudem so optimiert, dass es auf erschwinglicheren Hardwarekonfigurationen läuft, einschließlich einer NVIDIA RTX 3060 GPU mit 12 GB VRAM. In diesem Modus benötigt es etwa 9 GB Videospeicher bei einer maximalen Kontextlänge von 49.600 Tokens.
Vergleich mit anderen Modellen
| Modell | LCB Score (v5) | Codeforces Rating | HumanEval+ |
|---|---|---|---|
| DeepCoder-14B-Preview | 60,6 | 1936 | 92,6 |
| OpenAI o3-mini-2025-01-31 | 60,9 | 1918 | 92,6 |
| DeepSeek-R1-Distill-Qwen | 53,0 | 1791 | 92,0 |
Anwendungsbereiche und Grenzen
DeepCoder-14B-Preview eignet sich hervorragend für Aufgaben wie:
- Automatisierte Codegenerierung,
- Fehleranalyse und -korrektur im Quelltext,
- Erstellung von produktionsreifen Code-Snippets aus natürlicher Sprache.
Ein verbleibender Nachteil des Modells besteht in möglichen Einschränkungen bei langen Vorschlägen, insbesondere wenn die maximale Tokensanzahl auf Hardware-Ebene begrenzt ist.
Ausblick
Mit DeepCoder-14B-Preview etabliert Together AI einen neuen Standard in der Open-Source-Entwicklung von Codierungs-LLMs. Der zugängliche Trainingsprozess bietet der Community die Möglichkeit, das Modell zu replizieren, anzupassen und weiterzuentwickeln. Dies fördert nicht nur Innovationen bei Large Language Models, sondern treibt auch die Demokratisierung von Reinforcement-Learning-Technologien voran.
Quelle:
https://www.together.ai/blog/deepcoder